TINTOlib · Hybrid Neural Networks · Explainable AI
From Synthetic Images to Hybrid Neural Networks
Part II — How TINTOlib transforms tabular data into spatial representations, which methods should be preferred, and how CNNs, ViTs and XAI fit into the pipeline.
- Author: Manuel Castillo-Cara, PhD
- Affiliation: Dpt. of Artificial Intelligence, Universidad Nacional de Educación a Distancia (UNED), Spain
- Role: Researcher, Professor, and TINTOlib Python Library Developer
- License: CC BY-NC 4.0 unless otherwise stated.
Video overview
This post is part of a two-part technical summary derived from the conference Improving Deep Learning by Exploiting Synthetic Images, delivered in Peru.
The following short video provides an English overview of the main ideas discussed across both posts: why tabular data remains challenging for deep learning, how synthetic images can introduce spatial representations, and how TINTOlib connects structured data with computer vision, hybrid neural networks and explainable AI.
Additional material. The original conference recording is available in Spanish. The two blog posts provide an English technical synthesis and discussion based on that conference.
From theory to modelling
Part I introduced the theoretical motivation behind synthetic images for tabular data. The central point was that deep learning does not fail on tabular data because it is weak, but because many of its most successful architectures require structural assumptions that tables do not naturally provide.
This second part moves from the theoretical problem to the modelling pipeline. Once we accept that representation is central, the next questions are more practical:
- How should the spatial representation be constructed?
- Which transformation methods are methodologically preferable?
- How can synthetic images be connected with CNNs, Vision Transformers and hybrid neural networks?
- How can visual explainability be mapped back to original tabular variables?
These questions define the practical contribution of TINTOlib.
TINTOlib as an experimental framework
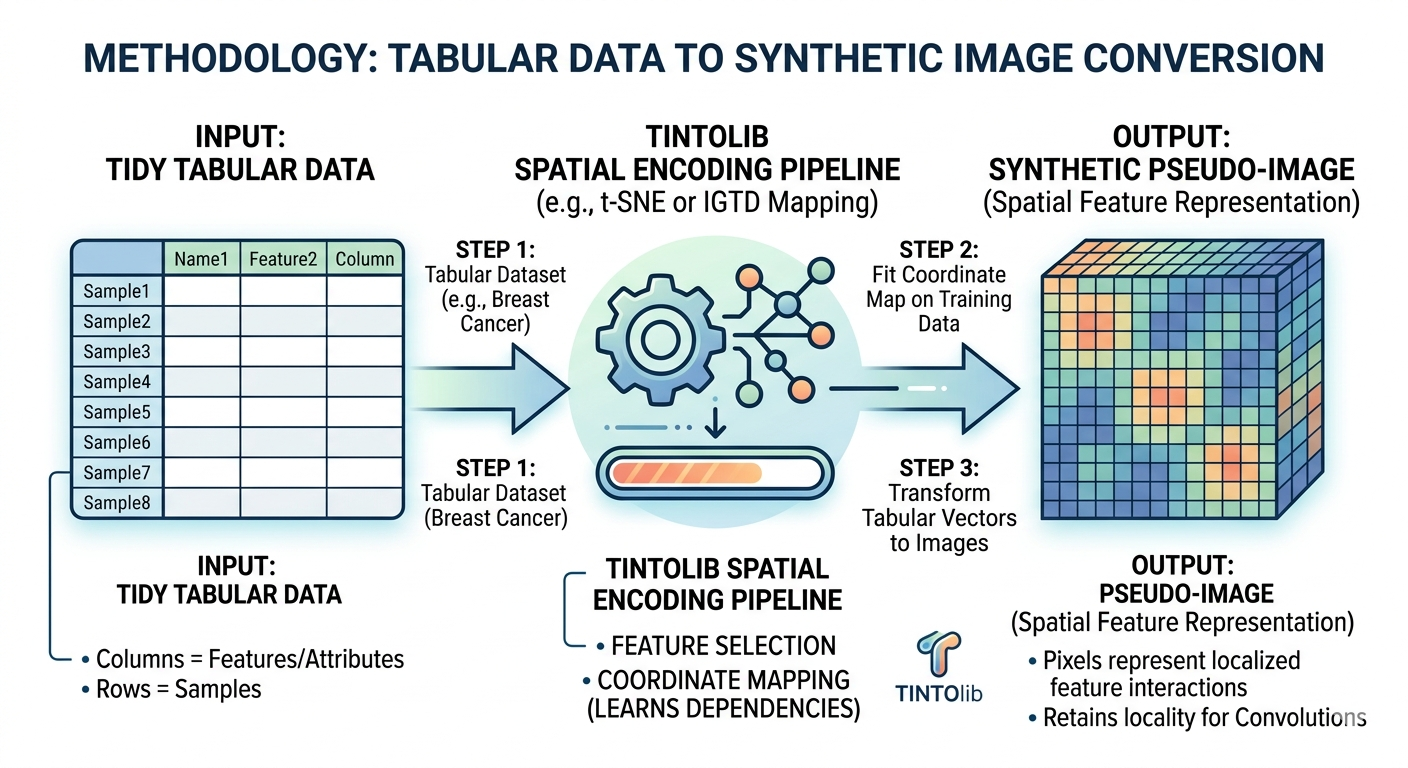
TINTOlib is not only a library for generating images. It is a framework for experimenting with a family of spatial representations for tabular data.
The value of a unified framework is methodological. Before TINTOlib, many tabular-to-image methods were implemented in separate repositories, with different APIs, assumptions and preprocessing requirements. This made systematic comparison difficult. TINTOlib provides a common interface that allows researchers to instantiate different methods, generate synthetic datasets and evaluate downstream architectures under more controlled conditions.
A typical experimental pipeline contains four stages:
Original tabular dataset
|
| train / validation / test split
v
Fit spatial transformation only on training data
|
| transform each split
v
Synthetic image dataset
|
| CNN / ViT / HyNN / XAI
v
Evaluation and interpretation
The separation between fitting and transforming is essential. The spatial layout must be learned only from the training data. If the validation or test set participates in the construction of the feature layout, data leakage occurs. The model would indirectly access information from the evaluation split before prediction.
Preferred families of spatial encodings
The most important methodological distinction is between methods that learn or optimize the spatial structure of the features and methods that remain dependent on the arbitrary column order.
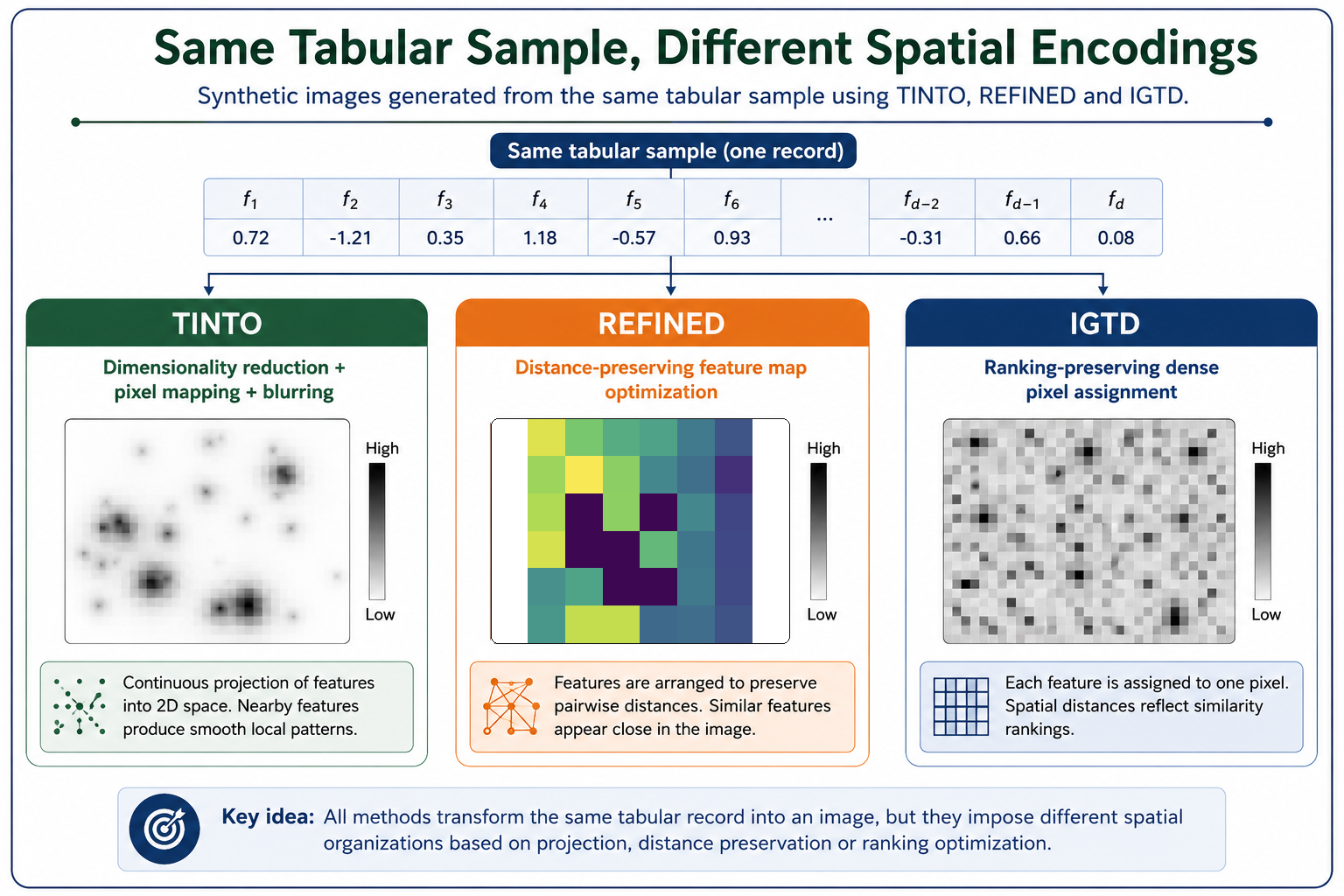
Methods such as TINTO, DeepInsight, IGTD, REFINED, Fotomics and recent unsupervised learning-based approaches such as Clusters are preferable when the goal is to build a spatial representation that reflects relationships in the data. They attempt to place related features close to one another through dimensionality reduction, similarity preservation, manifold learning, optimization or unsupervised representation learning.
This is the family of methods that best addresses the original problem. If tabular data have no natural spatial structure, the transformation method should construct one from the data, not inherit one from the arbitrary table layout.
By contrast, BarGraph, DistanceMatrix, Combination, SuperTML, BIE and FeatureWrap are more dependent on the original feature arrangement or on encoding schemes that can be influenced by how variables are ordered. These approaches can still be useful for comparison, teaching or specific datasets with meaningful order, but they should not be the first choice when working with generic tabular data whose column order is arbitrary.
The distinction can be summarized as follows:
Order-dependent encodings
|
| risk: inherit arbitrary column order
v
Useful as baselines, but not recommended as primary methods for unordered tables
Data-driven spatial encodings
|
| objective: learn or optimize feature geometry
v
Recommended for rigorous tabular-to-image experimentation
The methodological distinction becomes clearer when we compare the visual outputs of different transformation families. Some approaches generate images by imposing relatively direct or handcrafted encodings over the original feature arrangement. These methods can be useful for comparison, teaching, or specific datasets with meaningful feature order, but they may remain sensitive to the arbitrary ordering of the tabular columns.
Other methods attempt to construct a spatial representation from the data structure itself. In this second family, the image is not merely a visual formatting of the table; it is the result of a projection, optimization, similarity-preserving transformation, or unsupervised representation learning process. This distinction is central when synthetic images are used as input to CNNs, Vision Transformers, or hybrid neural architectures.
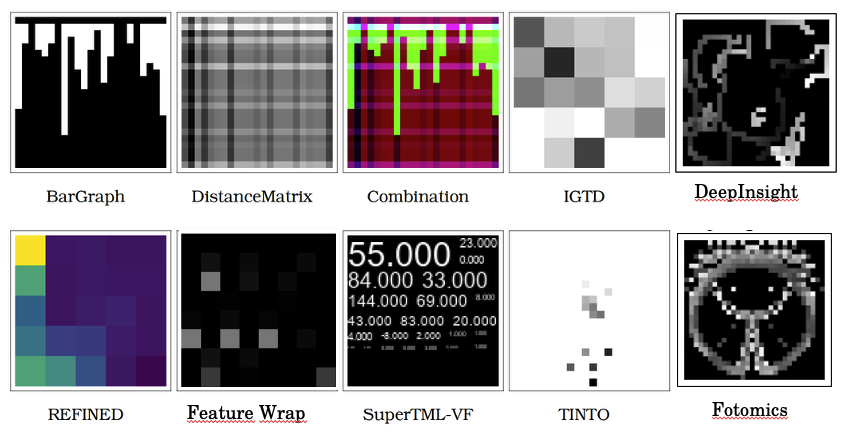 (Figure 1. Examples of supervised tabular-to-image transformation methods available in the TINTOlib ecosystem. These methods generate synthetic image representations from structured data, but they differ substantially in how they define or learn the spatial arrangement of the original variables. The methodological relevance of each image depends not only on its visual appearance, but also on whether its spatial structure reflects meaningful relationships between features.)
(Figure 1. Examples of supervised tabular-to-image transformation methods available in the TINTOlib ecosystem. These methods generate synthetic image representations from structured data, but they differ substantially in how they define or learn the spatial arrangement of the original variables. The methodological relevance of each image depends not only on its visual appearance, but also on whether its spatial structure reflects meaningful relationships between features.)
 (Figure 2. Examples of unsupervised tabular-to-image transformation methods. Unlike encodings that directly inherit the original column order, data-driven spatial methods aim to construct image-like representations from statistical, geometric or neighbourhood relationships among variables. This is essential when the original table has no natural spatial layout.)
(Figure 2. Examples of unsupervised tabular-to-image transformation methods. Unlike encodings that directly inherit the original column order, data-driven spatial methods aim to construct image-like representations from statistical, geometric or neighbourhood relationships among variables. This is essential when the original table has no natural spatial layout.)
Why blurring matters
One of the distinctive aspects of the TINTO method is the use of blurring. Blurring should not be understood as a cosmetic operation. It has a representational role.
When a feature value is projected into a pixel grid, the resulting image may be sparse or discontinuous. Blurring smooths local regions and can create more continuous spatial patterns. This may help convolutional filters detect local structures more effectively, because the information is not restricted to isolated pixels.
From a neural network perspective, blurring can be understood as a way of inducing local continuity. It transforms a discrete feature placement into a smoother visual signal. This does not guarantee better performance, but it creates a representation that is more aligned with the assumptions of convolutional processing.
The important point is that blurring must be evaluated empirically. Its usefulness may depend on the dataset, the image size, the density of the feature layout and the architecture used downstream.
Connecting synthetic images with CNNs and Vision Transformers
Once the tabular dataset has been transformed into synthetic images, several visual architectures become available.
A CNN processes the synthetic image through convolutional filters. If the feature layout has been constructed properly, nearby pixels may correspond to related variables, and local filters may capture interactions between them.
A Vision Transformer processes the image as a set of patches. This makes it possible to model longer-range relationships between regions of the synthetic image. For larger synthetic images or richer feature layouts, attention mechanisms may capture interactions that are not strictly local.
However, neither CNNs nor ViTs should be used as black-box replacements for classical models. The correct experimental design should include strong baselines:
- tree-based models such as Random Forest, XGBoost, LightGBM or CatBoost;
- an MLP trained directly on the original tabular data;
- several tabular-to-image methods;
- several image sizes;
- CNN, ViT and hybrid architectures;
- ablation studies with and without blurring;
- validation protocols that prevent data leakage.
Only under this type of comparison can we determine whether the synthetic image representation adds value.
Hybrid Neural Networks
A particularly relevant architecture is the Hybrid Neural Network. Instead of choosing between the original tabular data and the synthetic image, a hybrid model uses both.
A typical design includes:
- a tabular branch, usually an MLP that receives the original feature vector;
- an image branch, usually a CNN or ViT that receives the synthetic image;
- a fusion layer, where both representations are concatenated or combined;
- a prediction head for classification or regression.
This architecture is conceptually attractive because it avoids discarding the original tabular representation. The tabular branch can learn direct variable-level patterns, while the image branch can learn spatial interactions produced by the transformation method.
Since the main image of this post already summarizes the hybrid-neural-network idea, we will not duplicate that slide here. The important point is architectural: the hybrid model preserves the original tabular information while simultaneously exploiting a synthetic image representation derived from TINTOlib.
In indoor localisation, this design is especially meaningful. Wireless measurements can be represented as tabular features, but they may also contain latent spatial or structural patterns. A hybrid architecture can exploit both perspectives simultaneously.
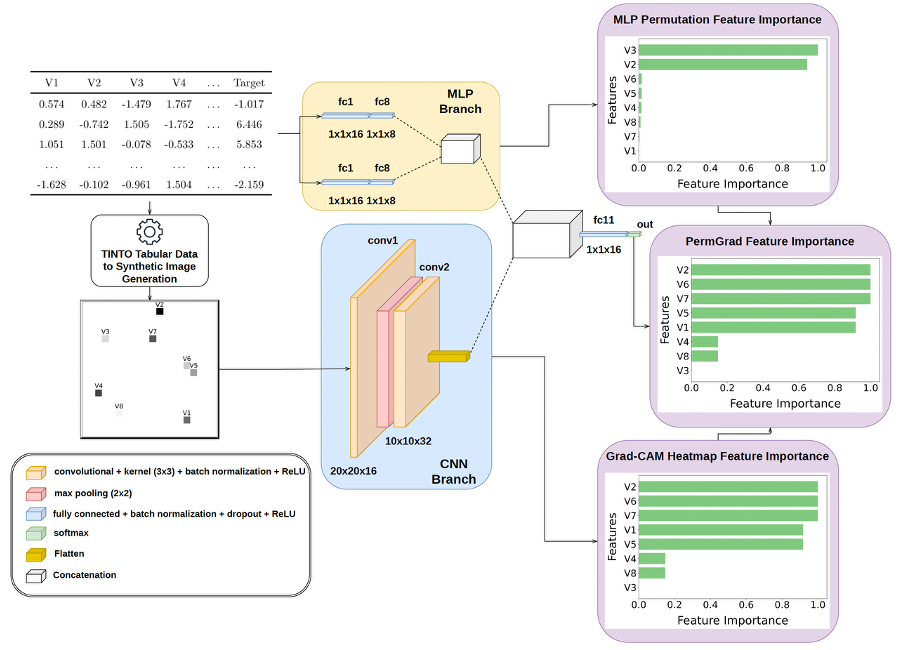
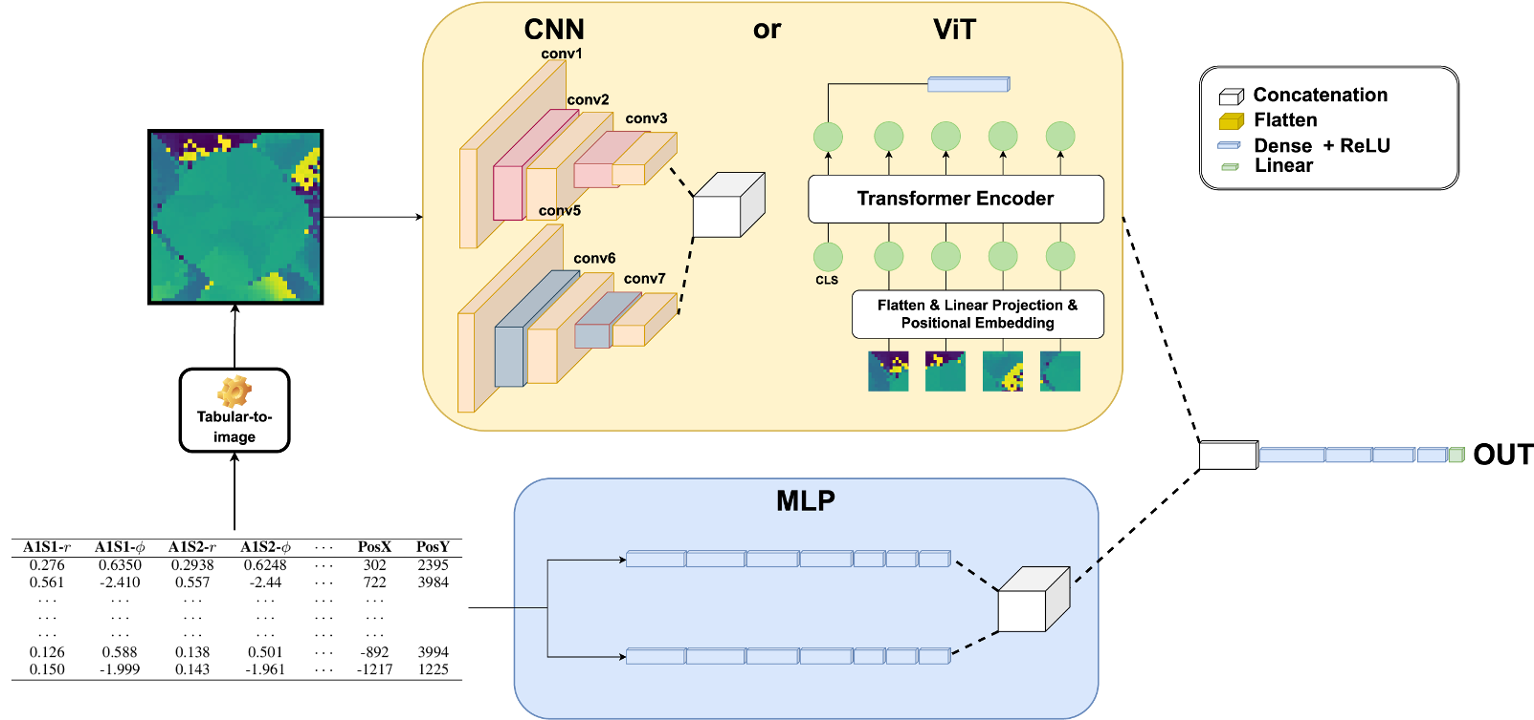 (Figure 3. A simplified illustration of the HyNN architecture. This figure shows that either CNN or ViT can be used as the vision component, while the MLP component processes tabular data directly. It also highlights the flexibility of the model, which allows for using only the vision or MLP part, illustrating the different architectures evaluated in this study.)
(Figure 3. A simplified illustration of the HyNN architecture. This figure shows that either CNN or ViT can be used as the vision component, while the MLP component processes tabular data directly. It also highlights the flexibility of the model, which allows for using only the vision or MLP part, illustrating the different architectures evaluated in this study.)
Explainable AI over synthetic images
Interpretability is one of the most important motivations for the synthetic image paradigm.
In a conventional neural network trained on tabular data, explanations are usually produced at the variable level. In a CNN trained on synthetic images, explanations can be produced visually. For example, methods such as Grad-CAM or saliency maps can identify regions of the synthetic image that were influential for the prediction.
The key step is to map those regions back to the original variables. Since the synthetic image is generated from a known feature layout, each pixel or region can be associated with one or more original tabular features. This allows a visual explanation to be translated back into the structured-data domain.
The first level of interpretation operates directly over the synthetic image. Since each region of the image is generated from a known spatial encoding of the original variables, visual attribution maps can be inspected not only as image explanations, but also as indirect explanations over the tabular feature space.
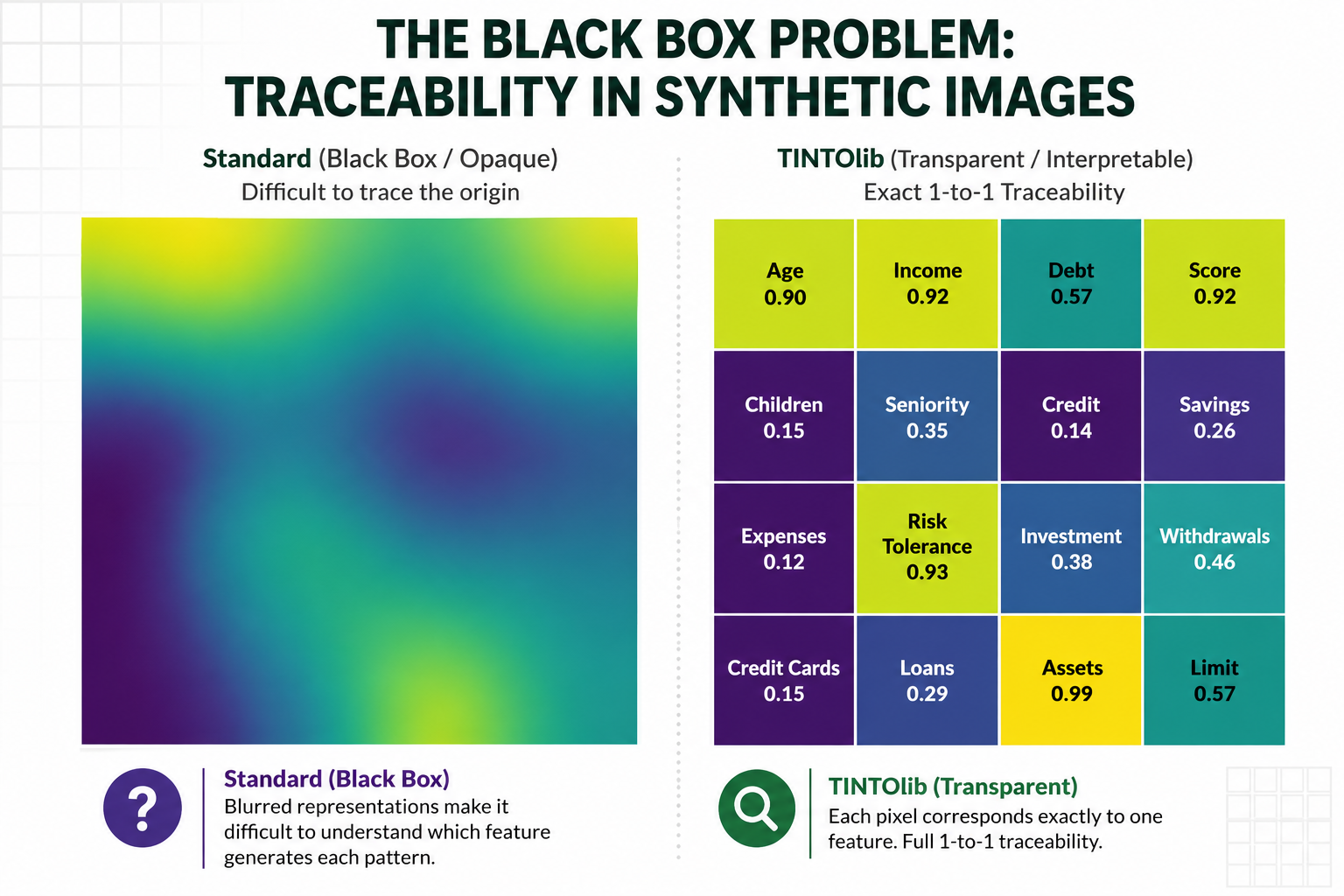 (Figure 4. AIX-based interpretation of synthetic tabular images in TINTOlib. Visual attribution maps can identify relevant regions of the synthetic image, which can then be related back to the original tabular variables through the known spatial encoding. This provides a bridge between image-based explainability and feature-level interpretation in structured data problems.)
(Figure 4. AIX-based interpretation of synthetic tabular images in TINTOlib. Visual attribution maps can identify relevant regions of the synthetic image, which can then be related back to the original tabular variables through the known spatial encoding. This provides a bridge between image-based explainability and feature-level interpretation in structured data problems.)
In hybrid architectures, this interpretability layer becomes even more relevant. The model can be analysed from two complementary perspectives: the tabular branch, which operates over the original feature vector, and the image branch, which operates over the synthetic spatial representation. This makes it possible to study whether both branches rely on consistent information or whether each one captures different aspects of the problem.
(Figure 5. Explainable AI workflow for hybrid neural networks combining tabular and synthetic image representations. The image branch enables visual attribution over the generated synthetic representation, while the tabular branch preserves direct access to the original variables. This makes it possible to connect spatial explanations with feature-level reasoning in hybrid deep learning models.)
This is one of the reasons why the method is not only useful for prediction. It also creates a framework for studying how neural networks use transformed tabular information.
Indoor localisation as a representative use case
The conference used indoor localisation as one of the representative domains for this paradigm. In MIMO-based and Bluetooth-based localisation problems, the input may consist of signal measurements, antenna-related variables or channel-state information. These variables are usually stored as tables, but they may contain complex structural dependencies.
Transforming these signals into synthetic images makes it possible to evaluate whether spatial encodings expose patterns that are difficult to exploit from the raw tabular representation. CNNs and ViTs can then process those patterns, while hybrid architectures can combine them with the original signal vector.
This does not mean that indoor localisation is the only application. The same idea can be applied to biomedical data, industrial monitoring, educational analytics, cybersecurity, financial risk modelling, sensor networks and many other domains where the input is tabular but the relationships between variables are complex.
What the paradigm does not claim
A rigorous interpretation of synthetic images for tabular data must avoid exaggerated claims.
The method does not claim that every table should become an image. It does not claim that CNNs will always outperform XGBoost. It does not claim that a synthetic image is semantically equivalent to a natural image.
The claim is more precise:
If the feature layout is constructed in a meaningful way, synthetic images can provide a spatial representation that allows visual and hybrid neural architectures to exploit relationships in tabular data.
This statement is testable. It requires benchmarks, ablations, strong baselines and careful validation.
Practical recommendations
For researchers and students working with TINTOlib, the following recommendations are important.
First, always split the data before fitting the transformation. Data leakage at the representation stage invalidates the evaluation.
Second, do not rely on order-dependent encodings as primary methods when the original feature order is arbitrary. Use them as baselines or teaching tools, but prioritize data-driven spatial encodings such as TINTO, DeepInsight, IGTD, REFINED, Fotomics and Clusters.
Third, compare against strong classical baselines. A synthetic image pipeline should not be evaluated only against weak neural models.
Fourth, evaluate several image sizes and architectures. The optimal spatial resolution may depend on the number of variables and the density of the feature layout.
Fifth, include interpretability analyses. One of the strengths of synthetic images is that they create a bridge between visual explanations and tabular variables.
Conclusion
Synthetic image generation from tabular data is not a superficial visualization technique. It is a representational strategy for connecting structured data with computer vision and hybrid neural architectures.
The central methodological requirement is that the image must have a meaningful spatial structure. If the image merely reflects the arbitrary order of the columns, the transformation reproduces the original limitation of tabular data. If, however, the spatial layout is learned or optimized from the relationships between variables, the resulting representation can provide a useful bridge toward deep learning.
TINTOlib provides the practical environment for exploring this idea. It enables systematic comparison of spatial encodings, integration with CNNs and Vision Transformers, development of hybrid neural networks and application of explainability techniques to synthetic tabular images.
The broader lesson is that deep learning performance depends not only on the architecture, but also on the representation. For tabular data, representation may be the decisive step.
References and related publications
The concepts presented in this tutorial are connected to the following research and software publications on TINTO, TINTOlib, tabular-to-image transformation, synthetic spatial representations, hybrid neural networks, indoor localisation and explainable artificial intelligence.
Research articles
Jiayun Liu, Manuel Castillo-Cara, Raúl García-Castro, Luis Orozco-Barbosa. Interpretable Hybrid Vision Transformer Architectures for MIMO-Based Indoor Localization using Synthetic Spatial Representations. IEEE Internet of Things. DOI: 10.1109/JIOT.2026.3696106
Jiayun Liu, Manuel Castillo-Cara, Raúl García-Castro. A Comprehensive Benchmark of Spatial Encoding Methods for Tabular Data with Deep Neural Networks. Information Fusion. DOI: 10.1016/j.inffus.2025.104088
Giovanny Mondragon-Ruiz, Jiayun Liu, Manuel Castillo-Cara, Raúl García-Castro. Interpretable CNN–KAN hybrid architectures for tabular data with synthetic image encoding. Information Processing and Management. DOI: 10.1016/j.ipm.2026.104954
Felipe Escalera-González, Manuel Castillo-Cara, Mariano Rincón-Zamorano, Luis Orozco-Barbosa. PermGrad: Interpretable Hybrid Neural Networks with synthetic images for tabular data. Knowledge-Based Systems. DOI: 10.1016/j.knosys.2026.116507
Manuel Castillo-Cara, Jesus Martínez-Gómez, Javier Ballesteros-Jerez, Ismael García-Varea, Raúl García-Castro, Luis Orozco-Barbosa. MIMO-Based Indoor Localisation with Hybrid Neural Networks. IEEE Journal of Selected Topics in Signal Processing. DOI: 10.1109/JSTSP.2025.3555067
Reewos Talla-Chumpitaz, Manuel Castillo-Cara, Luis Orozco-Barbosa, Raúl García-Castro. Blurring Image Techniques for Bluetooth-based Indoor Localisation. Information Fusion. DOI: 10.1016/j.inffus.2022.10.011
Software articles
Jiayun Liu, David González-Fernández, Manuel Castillo-Cara, Raúl García-Castro. TINTOlib: A Python library for transforming tabular data into synthetic images for deep neural networks. SoftwareX. DOI: 10.1016/j.softx.2025.102444
Manuel Castillo-Cara, Reewos Talla-Chumpitaz, Raúl García-Castro, Luis Orozco-Barbosa. TINTO: Converting Tidy Data into Image for Classification with 2-Dimensional Convolutional Neural Networks. SoftwareX. DOI: 10.1016/j.softx.2023.101391
Continue learning Artificial Intelligence
Explore practical courses on AI, Machine Learning, Deep Learning, Python, R and applied data science.

© Manuel Castillo-Cara, PhD. Content licensed under CC BY-NC 4.0 unless otherwise stated.